Translation & localization services
for the Italian language

Si possono considerare di ausilio alla traduzione, in senso lato, tutti gli strumenti informatici che in qualche modo elaborano il linguaggio umano: elaboratori di testi, software OCR (Optical Character Recognition), strumenti per il riconoscimento e la sintesi vocale, strumenti per la ricerca e sostituzione di testo, database testuali. Tuttavia, quando si parla di sistemi informatici per la traduzione, ci si riferisce in particolare a quei sistemi progettati appositamente per l'ambito traduttivo: da quelli che pretendono di sostituire il traduttore (traduttori automatici), a quelli che forniscono al traduttore strumenti per lo svolgimento di attività tradizionalmente svolte manualmente, quali vari tipi di analisi sul testo di partenza e/o di arrivo, la creazione, gestione e consultazione di glossari, le ricerche in corpora linguistici e la produzione del testo di arrivo. A tali applicazioni si fa riferimento collettivamente con il nome di CAT (Computer Aided Translation o Computer Assisted Translation, traduzione assistita da computer). Tuttavia, nell'uso comune, dall'insieme degli strumenti CAT viene solitamente esclusa la traduzione automatica (MT, Machine Translation), anche nella sua varietà assistita (HAMT, Human Aided Machine Translation), e il termine CAT si identifica quindi con quella che è più propriamente, anche se meno comunemente, detta MAHT (Machine Aided Human Translation).
I sistemi per la traduzione assistita (MAHT) attualmente più diffusi forniscono al traduttore professionista diversi strumenti, ma il ruolo centrale è svolto in essi dalla memoria di traduzione (TM, Translation Memory), tanto che il termine "strumento TM" viene spesso, sebbene in modo impreciso, usato interscambiabilmente con il termine "strumento CAT".
Una memoria di traduzione è un archivio elettronico in cui i testi di partenza in una lingua e i corrispondenti testi di arrivo in una o più lingue sono memorizzati in modo parallelo. I testi sono segmentati in unità minime di senso compiuto (frasi) e tali segmenti sono allineati in modo che a un segmento nella lingua di partenza corrisponda il proprio traducente in ciascuna delle lingue di arrivo.
Gli strumenti per la traduzione assistita consentono di creare una memoria di traduzione vuota e di alimentarla nel corso stesso della traduzione: le traduzioni prodotte sono infatti archiviate (in genere in modo automatico) nella memoria di traduzione. È anche possibile alimentare una memoria di traduzione da testi preesistenti mediante una procedura detta allineamento, a condizione che siano disponibili, in formato elettronico, sia il testo nella lingua di partenza, sia il corrispondente testo nella lingua di arrivo. L'allineamento consiste nella segmentazione dei testi di partenza e di arrivo, nella definizione delle corrispondenze tra i segmenti nelle due lingue (con interventi manuali più o meno estesi a seconda che lo strumento utilizzato implementi o meno algoritmi "intelligenti" per l'allineamento) e nell'inserimento di tali segmenti allineati nel database di memoria.
Quando si traduce utilizzando uno strumento CAT, lo strumento segmenta il testo da tradurre e per ogni segmento controlla se esistono corrispondenze nella memoria di traduzione. Se trova un segmento uguale (exact match, corrispondenza esatta) o simile (fuzzy match, corrispondenza parziale) nella lingua di partenza, presenta al traduttore il segmento corrispondente nella lingua di arrivo. Il traduttore potrà accettare la traduzione suggerita ed eventualmente correggerla come necessario, oppure ignorarla e inserire una traduzione ex-novo.
La maggior parte degli strumenti CAT consente inoltre di cercare nella memoria di traduzione singoli termini o espressioni: anche se un termine non è presente nei glossari disponibili, sarà quindi possibile verificare come è stato tradotto in precedenza.
Una memoria di traduzione è uno strumento potente per la gestione di testi ripetitivi (documentazione tecnica in primo luogo, ma anche testi legali e commerciali), garantendo coerenza stilistica e terminologica e tempi di traduzione ridotti.
A differenza delle memorie di traduzione, le risorse terminologiche non sono un concetto introdotto con l'applicazione della tecnologia informatica al campo della traduzione. I traduttori hanno sempre utilizzato tali risorse, sotto forma di dizionari e glossari cartacei. È quindi ovvio che, con l'avvento della rivoluzione informatica, i primi strumenti concepiti quale ausilio per i traduttori siano stati strumenti di gestione della terminologia. I computer hanno facilitato tale gestione, che in precedenza avveniva mediante liste o schede, grazie all'utilizzo di applicazioni generiche di gestione di basi di dati o di applicazioni progettate in modo specifico per la gestione della terminologia.
Pressoché tutti gli strumenti CAT/TM comprendono componenti specifici per la gestione della terminologia. L'innovazione di maggior rilievo è costituita dal riconoscimento terminologico automatico: durante la traduzione, i termini presenti sia nel testo da tradurre, sia nel glossario o nei glossari associati al progetto, sono individuati in modo automatico e i traducenti sono presentati sullo schermo in tempo reale. Alcuni strumenti inseriscono automaticamente tali termini nella traduzione; tutti mettono a disposizione metodi rapidi per la loro selezione e inserimento nel testo, riducendo i tempi di digitazione e le possibilità di refusi.
L'applicazione pratica della tecnologia informatica al campo della traduzione ha una storia relativamente lunga: già nei primi anni '50, come supporto alle attività spionistiche della guerra fredda, erano stati progettati sistemi per la traduzione automatica. L'entusiasmo per le potenzialità intraviste negli elaboratori elettronici e le teorie linguistiche allora prevalenti (strutturalismo) portavano a ritenere che la completa e soddisfacente sostituzione dei traduttori umani con i computer fosse solo una questione di tempo. Quindici anni dopo, con il famoso rapporto ALPAC del 1966, tali illusioni si raffreddarono e la ricerca nel campo della traduzione automatica rallentò, mentre si cominciarono a cercare modi di mettere la tecnologia informatica al servizio del traduttore umano.
Le prime soluzioni consistevano essenzialmente in banche dati terminologiche. Dati i costi elevati delle tecnologie informatiche, negli anni '70 tali sistemi erano tuttavia confinati ad alcune grandi aziende. Tra la fine degli anni '70 e l'inizio degli anni '80 cominciarono a circolare idee che costituivano la base del concetto di memoria di traduzione:
"It must in fact be possible to produce a program which would enable the word processor to 'remember' whether any part of a new text typed into it had already been translated, and to fetch this part, together with the translation which had already been done, and display it on screen or print it out, automatically." [P. J. Arthern, Aids unlimited: the scope for machine aids in a large organization, in Aslib Proceedings volume 33, no. 8, Machine Aids for Translators, Aslib, London, 1981.]
Nel corso degli anni '80, con l'apparizione dei primi personal computer, tali sistemi cominciarono effettivamente a essere realizzati. Il pioniere è stato probabilmente TSS (Translation Support System), un software per sistema operativo OS/2 realizzato da ALPS, una società statunitense produttrice di software per applicazioni linguistiche, poi divenuta Alpnet. TSS fu realizzato attorno alla metà degli anni '80 e fu adottato da alcune grandi società, tra le quali IBM, per la propria attività di traduzione interna.
La seconda metà degli anni '80 vede un grande fermento nel settore: la società olandese INK realizza nel 1987 un sistema ispirato a TSS e integrato da un componente terminologico (TermTracer), producendo un pacchetto denominato Text Tools. La società Trados, fondata nel 1984, ottiene il diritto di commercializzare tale pacchetto in Germania. Lo stesso anno la società svizzera Star AG, specializzata in traduzioni tecniche, realizza per i collaboratori interni un software di traduzione denominato Transit, funzionante sotto DOS. Diverse altre aziende realizzano strumenti simili a uso interno.
La commercializzazione di tali pacchetti al di fuori delle grandi aziende viene avviata faticosamente nei primi anni '90. Nel 1990 esce la prima versione di Trados MultiTerm per DOS. Nel 1992 IBM lancia sul mercato il suo SAA AD/Cycle Translation Manager/2 (TM/2) per OS/2. Lo stesso anno fa il suo esordio sul mercato Trados Translator's Workbench per DOS. L'anno successivo Atril realizza e immette sul mercato Déjà Vu per Windows. Nel 1994 anche Star mette in commercio la versione per Windows del proprio sistema. Tuttavia i prezzi elevati di questi strumenti (dell'ordine di diversi milioni di vecchie lire) e i requisiti hardware non contenuti ne rallentano la diffusione fra i traduttori indipendenti.
Nello stesso quinquennio vedono la luce diversi altri software basati sul concetto di memoria di traduzione, che hanno però scarso successo e il cui sviluppo viene abbandonato. Nella seconda metà degli anni '90, mentre alcuni dei software nati agli inizi del decennio conquistano una sempre maggiore popolarità fra i traduttori, grazie anche a un sostanziale ribasso dei prezzi, fanno la loro comparsa prodotti nuovi, tra i quali SDLX (1998) e Wordfast (1999).
Il vertiginoso sviluppo di Internet negli anni '90 portò a uno scambio di dati frenetico e senza precedenti tra i sistemi informatici più disparati nelle più diverse parti del mondo. Presto ci si rese conto della necessità di definire degli standard che permettessero di superare i numerosi problemi di compatibilità emersi. Il World Wide Web Consortium, fondato nel 1994 per promuovere l'interoperabilità nel nuovo spazio virtuale, cominciò a definire formati di interscambio dei dati basati su testo con marcatori, derivati dal metalinguaggio di marcatura SGML la cui prima definizione risale al 1980. Dall'SGML derivano tra gli altri l'HTML, il linguaggio dominante in Internet, e l'XML, un'implementazione dell'SGML che promette una maggiore potenza e flessibilità rispetto all'HTML e la cui prima definizione risale al 1998.
Alla definizione di tali standard generici per il Web seguirono a ruota le definizioni di vari standard riguardanti in modo specifico il settore della traduzione. Anche tali standard sono basati sull'SGML e in particolare sull'XML.
Lo standard più diffuso è quello per l'interscambio delle memorie di traduzione: TMX (Translation Memory eXchange). Sviluppato dal gruppo OSCAR (Open Standards for Container/Content Allowing Re-use), parte della LISA (Localization Industry Standards Association), nel 1998, è basato su XML ed è supportato da pressoché tutti gli strumenti CAT/TM, anche se non sempre in modo perfettamente interoperabile.
Standard recentissimo è lo XLIFF (XML Localisation Interchange File Format), sviluppato nel 2003 da OASIS per il settore della localizzazione e il cui successo è ancora da determinare.
Per quanto riguarda la terminologia, il panorama è più confuso. Coesistono, tra gli altri, i seguenti standard relativi al formato dei database lessicali e terminologici:
I software per la traduzione assistita mettono a disposizione diverse funzioni per assistere il traduttore nelle varie fasi del suo lavoro. Alcune funzioni sono offerte da tutti gli strumenti, altre solo da alcuni. Riprendendo liberamente la classificazione operata da Melby (Alan K. Melby, Eight Types of Translation Technology, 1998), distinguiamo:
Altre funzioni che gli strumenti per la traduzione assistita possono avere e che non rientrano in questa classificazione sono: conteggio parole e caratteri ai fini della fatturazione, funzioni di filtro per la gestione di diversi formati di file in importazione ed esportazione, funzioni di editing nel corso della traduzione, funzioni di gestione dei progetti, funzioni specifiche per la localizzazione delle interfacce software.
Prendiamo in considerazione alcuni tra gli strumenti più diffusi (Déjà Vu, Transit, SDLX, Trados, Wordfast). Tutti questi strumenti dispongono delle funzioni a livello di segmento elencate in precedenza: allineamento di traduzioni precedenti, segmentazione del testo da tradurre, analisi e pretraduzione, consultazione automatica della memoria, inserimento automatico dei segmenti dalla memoria nel testo e viceversa, desegmentazione e produzione dei documenti di destinazione. La distinzione più evidente è quella tra strumenti che offrono al traduttore un ambiente di traduzione proprietario (Déjà Vu, Transit, SDLX) da una parte, e strumenti che si appoggiano a un editor di testi esistente, tipicamente Microsoft Word (Trados WorkBench1, Wordfast), dall'altra. I secondi consentono al traduttore che si avvicina per la prima volta agli strumenti CAT un approccio più morbido con la nuova tecnologia, grazie all'ambiente di lavoro già in parte noto e alla possibilità di visualizzare i documenti da tradurre nel formato originale. I primi, d'altro canto, offrono il vantaggio di rendere del tutto trasparente per l'utente il processo di conversione dei file da uno qualsiasi dei formati supportati all'ambiente di lavoro unificato e di riconversione al formato originale, nonché l'opzione di presentare tutti i file del progetto insieme in un'unica finestra, come se fossero un solo file.
Vedremo ora le caratteristiche di alcuni degli strumenti più utilizzati nel settore e il modo in cui tali strumenti implementano le funzioni citate. Esamineremo: Trados (Translator's WorkBench e MultiTerm), Atril Déjà Vu, Star Transit e Termstar, SDLX, Wordfast.
Il sistema più noto e diffuso nel settore delle traduzioni non è in realtà una singola applicazione, ma piuttosto una suite di programmi, ciascuno specializzato in un particolare compito. Il componente centrale è il Translator's WorkBench, un programma che gestisce le memorie di traduzione e l'interazione fra Microsoft Word e i database di memoria e terminologico, grazie anche ad alcune macro installate in Word. Il traduttore lavora tenendo contemporaneamente aperti Microsoft Word, Translator's WorkBench ed eventualmente MultiTerm. Traduce operando su segmenti di testo tramite le macrodi Word installate da Trados, mentre nel Translator's WorkBench sono visualizzati i suggerimenti della memoria di traduzione ed eventualmente del glossario. Tramite il Translator's WorkBench è inoltre possibile creare, importare ed esportare memorie di traduzione, eseguire l'analisi dei file da tradurre ed elaborare i file tradotti in modo da ripristinarne il formato originario e, se necessario, aggiornare la memoria (clean-up).

Traduzione svolta in Microsoft Word con l'ausilio di Trados Translator's WorkBench
Déjà Vu è un'applicazione che offre al traduttore un ambiente di lavoro unificato per la gestione di database di memoria, terminologici e di progetto. Tutti i database utilizzati sono in formato Microsoft Access. Déjà Vu mette a disposizione strumenti potenti e flessibili per l'importazione, l'esportazione e la manipolazione dei propri database, tra cui il linguaggio SQL (Structured Query Language). Progetti grandi e complessi, comprendenti un gran numero di file anche di formati diversi, possono essere gestiti come un unico grande file, sul quale è possibile applicare operazioni di ricerca e sostituzione, filtro e propagazione.

L'interfaccia di Atril Déjà Vu
Star offre due applicazioni distinte ma strettamente integrate: Transit, l'ambiente di traduzione vero e proprio, e TermStar, per la gestione della terminologia. Transit ha un concetto di memoria di traduzione originale e flessibile: anziché memorizzare le coppie di segmenti in un apposito database, utilizza i file stessi del progetto corrente e di progetti precedenti (segmentati, indicizzati e tradotti) come memoria di traduzione. A ogni progetto è possibile inoltre associare un numero qualsiasi di database terminologici.

L'interfaccia di Star Transit
SDLX presenta diverse somiglianze con Déjà Vu, a partire dall'interfaccia tabellare e dall'utilizzo del formato Microsoft Access per i database di memoria e terminologici. La formattazione del documento originale è rappresentata visivamente, all'interno del programma, da diversi colori di sfondo del testo. Pratica la funzione di visualizzazione dell'anteprima del documento tradotto.

L'interfaccia di SDLX
A differenza degli altri strumenti, Wordfast non è un vero e proprio programma, ma un insieme di macro di Microsoft Word. La modalità di elaborazione dei documenti è molto simile a quella di Trados. Nato come strumento gratuito di ripiego per i traduttori che non potevano permettersi l'acquisto di applicazioni costose, si è evoluto in uno strumento sofisticato, che offre funzionalità non presenti in Trados e apprezzate dai traduttori, a un costo sensibilmente inferiore rispetto agli altri strumenti.

Traduzione svolta in Microsoft Word con l'ausilio delle macro di Wordfast
Lo strumento di gestione della terminologia di Trados è MultiTerm. Nelle versioni più recenti è stato introdotto MultiTerm iX, un nuovo strumento che, se da una parte rende possibili alcune operazioni, quali l'inserimento interattivo di termini durante la traduzione, in precedenza non possibili con MultiTerm, d'altra parte aumenta la complessità di uno strumento che già non aveva la facilità d'uso tra i suoi punti di forza. Punti di forza di MultiTerm sono la capacità di gestione di più lingue, la strutturazione in concetti e l'ampia configurabilità degli attributi.

Schermata di Trados MultiTerm
Alcune versioni di Trados offrono anche un componente per l'estrazione terminologica.
La versione più recente di Déjà Vu (Déjà Vu X) integra tutti gli strumenti, compresa la gestione della terminologia, in un'interfaccia unificata. Anche in Déjà Vu la terminologia è organizzata per concetti, con la possibilità di gestire più lingue nello stesso database e di definire attributi personalizzati. Particolarmente apprezzabile in Déjà Vu è una relativa facilità d'uso, pur con la maggiore complessità introdotta con la versione X, e l'ampia scelta di formati di importazione ed esportazione, che facilita lo scambio di dati con clienti e colleghi che utilizzano altre applicazioni.

Schermata di Déjà Vu con aperto un database terminologico
Déjà Vu dispone di una funzione di estrazione terminologica integrata nel Lexicon (un glossario integrato nel progetto).
Transit è fornito insieme a Termstar, un componente di gestione della terminologia potente e flessibile. I termini sono organizzati per concetti ed è possibile definire diversi attributi e gestire più lingue. Le funzioni di importazione ed esportazione sono abbastanza potenti anche se piuttosto macchinose.

Schermata di TermStar
La versione più recente di Transit (XV) offre una funzione di estrazione terminologica.
I database terminologici di SDLX, così come quelli di memoria, sono in formato Microsoft Access. Anche in SDLX la terminologia è organizzata per concetti, con la possibilità di gestire più lingue nello stesso database e di definire attributi personalizzati. È possibile importare ed esportare i termini in formati ampiamente compatibili con altre applicazioni. Il componente di gestione terminologica di SDLX è SDL TermBase.

Schermata di TermBase
I glossari di Wordfast offrono un'estrema semplicità di gestione e la maggiore compatibilità con le altre applicazioni: si tratta infatti di glossari in semplice formato testo delimitato da tabulazione. In quanto tali possono essere aperti da molte delle applicazioni più comuni, tra cui Word ed Excel.

Glossario Wordfast aperto in Excel
Il risvolto negativo di tale semplicità di gestione è costituito da una minore potenza: i glossari possono essere unicamente bilingue e non sono strutturati per concetti. Sono quindi inadatti a soddisfare le esigenze dei terminologisti, mentre sono generalmente più che sufficienti per assistere il lavoro dei traduttori.
In +Tools, una suite di strumenti gratuita che accompagna Wordfast, è disponibile anche una funzione di estrazione terminologica.
Tutti gli strumenti presentati dispongono delle funzioni a livello di segmento elencate in precedenza: allineamento di traduzioni precedenti, segmentazione del testo da tradurre, analisi e pretraduzione, consultazione automatica della memoria, inserimento automatico dei segmenti dalla memoria nel testo e viceversa, desegmentazione e produzione dei documenti di destinazione.
Trados Translator's WorkBench opera su documenti Microsoft Word (DOC ed RTF). Mediante appositi filtri o componenti è in grado di gestire altri formati, tra i quali HTML, Excel, PowerPoint, FrameMaker, RC.
I documenti possono essere segmentati prima di cominciare a tradurre, mediante la funzione di pretraduzione, oppure nel corso della traduzione stessa. Ogni segmento (frase) del testo originale viene sostituito, all'interno del documento stesso, da un'unità di traduzione così strutturata:
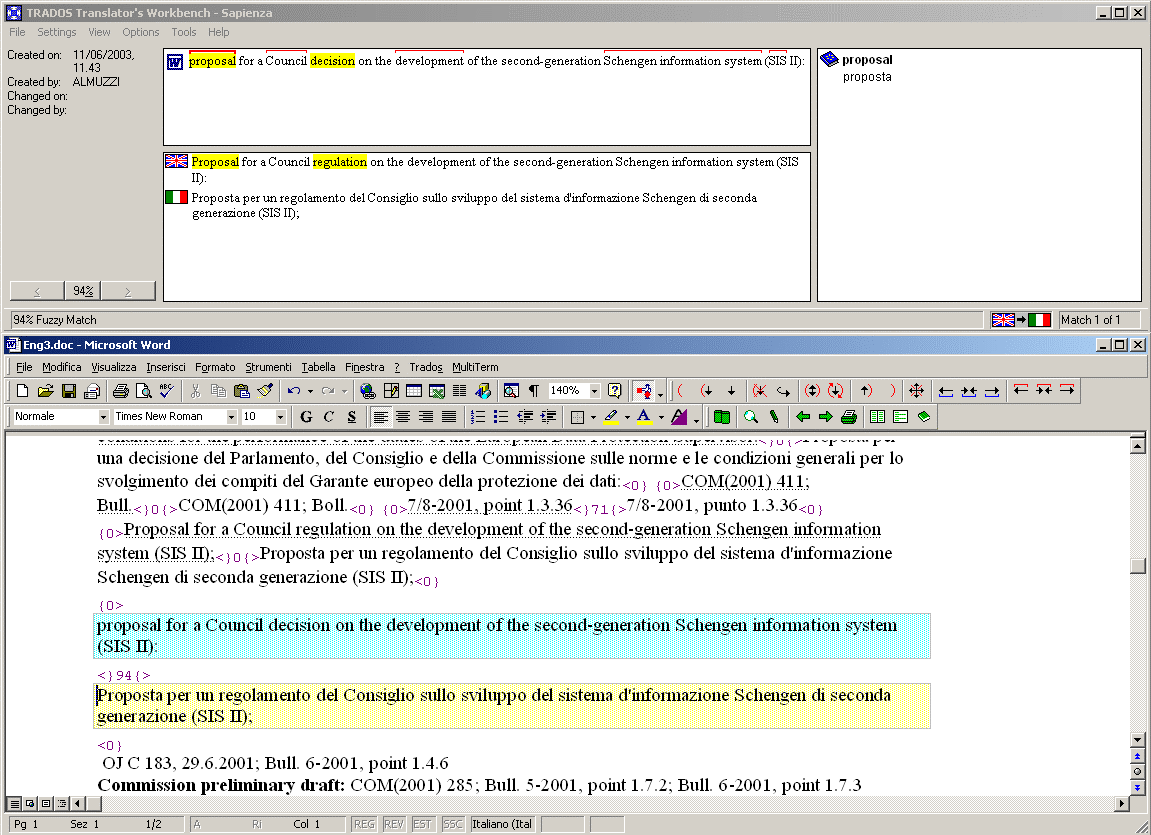
Fuzzy match in Trados
Nell'ambiente di lavoro unificato di Déjà Vu è possibile creare progetti comprendenti più tipi di file, tra cui anche file segmentati da Trados (DOC, RTF, BIF, TTX) e Wordfast. I file sono importati da appositi componenti, detti filtri, i quali, in modo trasparente per l'utente, convertono i file nel formato adottato da Déjà Vu e li segmentano, per poi presentarli al traduttore in formato tabellare. Le informazioni originarie sulla formattazione sono sostituite da codici rappresentati da numeri racchiusi tra parentesi graffe. Nello stesso ambiente avviene l'interazione con i database di memoria e terminologici (è possibile associarne più d'uno al progetto, a seconda della versione di Déjà Vu installata).
Nella schermata seguente vediamo la stessa corrispondenza parziale mostrata sopra per Trados, con la stessa percentuale di somiglianza e l'evidenziazione delle differenze tra segmento in memoria e segmento da tradurre:

Fuzzy match in Déjà Vu
Anche Transit dispone di a un ambiente di lavoro unificato in cui importare vari tipi di file mediante una vasta scelta di filtri (alcuni dei quali forniti separatamente). La presentazione è però diversa: il documento di partenza e quello di arrivo sono visualizzati in due finestre distinte, mentre i segmenti sono delimitati da tag numerati.
Ecco un esempio di fuzzy match con una percentuale di somiglianza dell'80% e l'evidenziazione delle differenze:

Fuzzy match in Transit
Come già detto, l'aspetto di SDLX è simile a quello di Déjà Vu. Anche SDLX dispone di diversi filtri di importazione file. Qui sotto vediamo lo stesso fuzzy match già illustrato per Trados e Déjà Vu. Notiamo come la percentuale di somiglianza, qui del 91%, non sia la stessa individuata dagli altri strumenti. In effetti non esiste un criterio unico per la determinazione di tale percentuale, ma ogni strumento adotta criteri propri.

Fuzzy match in SDLX
Wordfast segmenta i documenti, prima della traduzione o durante la stessa, in modo simile a Trados, facendo ricorso unicamente a macro di Word. Le memorie di traduzione, così come i glossari, sono in formato testo delimitato da tabulazione, quindi facilmente gestibili e scambiabili. Non memorizzano tuttavia alcuna informazione sulla formattazione, che, dove necessario, dovrà essere applicata dal traduttore.
Un vantaggio rispetto a Trados è rappresentato dalla gestione dei segmenti privi di corrispondenza in memoria: attivando le opportune opzioni, è possibile inserire nel segmento le traduzioni dei termini eventualmente presenti nel glossario, che andranno così a sostituire i termini originali. Questo meccanismo di "assemblaggio" della traduzione è offerto in modo più completo da Déjà Vu (in grado di operare inserimenti dai glossari anche nei fuzzy match) e in modo parziale da Transit (inserimenti solo nei fuzzy match).
Ecco infine in Wordfast lo stesso fuzzy match già visto per Trados, Déjà Vu e SDLX, con un valore di corrispondenza ancora diverso (88%), a conferma della non uniformità dei criteri di valutazione:

Fuzzy match in Wordfast
Le funzioni operanti a livello di segmento tipiche di questi strumenti offrono indiscutibili vantaggi quando si debbano gestire documenti con un alto grado di ripetitività. Non è un caso che vengano largamente usati per la documentazione tecnica, quando devono essere tradotte nuove edizioni che sostituiscono le precedenti, ma dove una buona parte del testo resta invariata. Ampio, direi universale, l'uso che se ne fa per le traduzioni di carattere informatico, sia perché la ripetitività è elevata, sia per la maggiore propensione delle aziende produttrici di software ad abbracciare tecnologie avanzate. Tuttavia vantaggi non trascurabili sono ottenibili anche in altri settori, come quello commerciale, legale, turistico o medico, per l'aiuto fornito sotto l'aspetto terminologico. Anche chi si occupa di traduzioni di sceneggiature afferma di ricavare benefici da una gestione informatizzata della terminologia. Diverso ovviamente il discorso per la letteratura: quanto più ci si avvicina alla letteratura "pura", e in particolare alla poesia, tanto meno si nota l'utilità di strumenti del tipo qui illustrato.
Al primo impatto con uno strumento CAT, l'impressione può essere sfavorevole: il testo da tradurre viene scomposto e presentato in un formato spesso distante da quello originale, creando difficoltà nel cogliere il contesto. Generalmente è utile lavorare avendo sott'occhio una copia, su schermo o carta, del documento originale. Si può inoltre tendere a essere ipercritici rispetto ai risultati forniti dal computer e a concludere che la modalità tradizionale, manuale, è preferibile; o, viceversa, ad affidarsi troppo ai suggerimenti del programma, per fretta o soggezione nei confronti dello strumento, producendo così traduzioni di scarsa qualità. Come per qualsiasi strumento, anche per gli strumenti di ausilio alla traduzione i benefici dipendono dall'uso che se ne fa. Pur utilizzando uno strumento di traduzione assistita, il traduttore deve restare padrone del processo di traduzione e continuare a mantenerne la responsabilità.
Una causa di abbassamento di qualità della traduzione può essere dovuta al desiderio di molti committenti di utilizzare gli strumenti CAT unicamente al fine di contenere i costi e ridurre i tempi. Ciò porta a fare eccessivo affidamento su operazioni automatiche come la pretraduzione, utilizzando in definitiva i traduttori come strumenti accessori della macchina, invece di considerare la macchina quale strumento al servizio del traduttore.
Molti traduttori rilevano difficoltà nell'uso di questi strumenti, sia per un'insufficiente preparazione tecnico-informatica di base nella formazione classica del traduttore, sia perché tali strumenti presentano in effetti una certa complessità e non hanno probabilmente ancora raggiunto la completa maturità e stabilità. Molti di coloro che li utilizzano percepiscono di sfruttare solo una minima parte del loro potenziale.
È possibile frequentare corsi di formazione mirati a un particolare strumento. Per i corsi ci si può rivolgere ai produttori stessi, ai formatori autorizzati o a professionisti indipendenti. Corsi e seminari sono inoltre spesso organizzati dall'AITI (Associazione Italiana Traduttori e Interpreti, www.aiti.org) o da altre associazioni di traduttori italiane o internazionali.
Trados: http://www.trados.com
Déjà Vu: http://www.atril.com
Transit: http://www.star-group.net
SDLX: http://www.sdlintl.com
Wordfast: http://www.champollion.net
Alessandra Muzzi - 13 marzo 2004
1. Un discorso a parte andrebbe fatto per Trados TagEditor, che è sì un ambiente proprietario, ma che ricalca il modo di lavorare in Microsoft Word, per quanto riguarda sia la segmentazione del testo, sia la possibilità di lavorare su un solo file alla volta.
